Introduction
Hi there, this is Nathan from Linker's developers team. Today I'll be writing about the things we learned when implementing Elasticsearch on a Japanese database.
Purpose
There are a countless guides for setting up and using Elasticsearch, but the majority of them are focused around English datasets. This blog post is intended as a collection of tips/wisdoms wish we had known from the beginning when using Elasticsearch on a majority-Japanese database.

Is this a guide for setting up Elasticsearch?
No. This blog post is not a comprehensive guide for implementing Japanese Elasticsearch, but there are some good resources available. Here are a few:
Who is this post for?
- For developers who are either already using Elasticsearch with Japanese or are planning to.
- For developers who plan to use Elasticsearch with Rails
Programming language, tooling, etc.
Most of the concepts in this blog post are universal. However, we use Ruby, more specifically Ruby on Rails, at Linkers. Examples will be written in Ruby.
There will be some Ruby specific recommendations at the bottom of this post as well.
Contents
- Introduction
- Tips
- Conclusion
- Acknowledgements
- References
Tips
1. Indexing Japanese Strategies
In order to search for anything with Elasticsearch you'll need to index a dataset first. There are many strategies for indexing data and they each have different tradeoffs. By default Elasticsearch is not optimized to index Japanese, but there are a number of approaches/tools out there that make it easier.
What sorts of issues/optimizations are you talking about?
- Ability to understand recognize Japanese grammar
- Example: there are no spaces between words, which makes it difficult to analyze
- Example: there are many different conjugations for verbs, adjectives, etc.
- Ability to search kanji with hiragana, hiragana with katakana, etc.
- Japanese can be written using 全角 (full width) and/or 半角 (half width) characters
1A: The brute force method: n-grams
If you're looking for the most simple search where characters match exactly then you might considering the n-gram approach.
2 つの方法で単語をアナライズする 日本語は単語の切れ目がわかりにくいので、転置インデックスのキーは主に次の2つの手法で作成します。 (reference)
As a strategy it's a language agnostic approach, meaning it would work for Japanese, Chinese, English, etc..
The basic concept is to group characters in chunks of size n and index those chunks. Elasticsearch supports this kind of analysis out of the box without any extra tooling. There are plenty of resource online on how to set that up.
👍 What are the benefits?
- Robust and predictable
- Fast
👎 What are the downsides?
- Search input will need to match the results exactly. Any mis-typed characters will quickly spoil the search results.
- Lack of lexical awareness means it's not great for auto-complete, searching kanji with hiragana, etc..
- Searching for kanji with hiragana, or katakana with hiragana (or vice-versa) is difficult to implement
1B: The morphological approach: Kuromoji (形態素解析)
Kuromoji is an Elasticsearch analyzer maintained by Atilikia that uses a dictionary approach to creating indexes.

👍 What are the benefits?
- Ability to search kanji, hiragana, and katakana, interchangeably
- Ability to recognize different grammatical attributes such as verb conjugations, etc.
👎 What are the downsides?
Kuromoji is vulnerable to abbreviations, new words, slang, etc.. Depending on your use case it may actually be better to use N-grams.
With morphological analysis, there is weakness for new words. Since it's dictionary-based, words that are not in the dictionary cannot be detected. (there is little search noise, but there are many omissions in the search)
形態素解析では、新語(未知語)に弱い。また、辞書ベースの場合、辞書にない単語は検出不能。(検索ノイズが少ないが、検索漏れが多い) (reference)
With the Kuromoji approach you are much more reliant on the score of the search results. Compared to the n-gram approach the reason that a search result is a match may be much less obvious. We'll go in this in more detail later in the post (when talking about dealing with too many results).
So, what did we use?
✅ We've opted for the Kuromoji approach. In our use case, the positives far outweighed the negatives. This decision, however, meant we did need to compensate for a few edge cases.
2. Keep the number of search results low
When we first starting using Elasticsearch, we wanted to give the customer as many matches as possible. However, it quickly became apparent that we were returning too many results and it was necessary to update our strategy. The necessity became even more important when the number of results crossed 10,000.
💡 Did you know: Elasticsearch has a "max_result_window" size of 10,000.
This means at most 10,000 results are put into the memory heap at a time. When this threshold is exceeded then display the total number of search matches, search order, and a number of other features quickly lose their value.
The "max_result_window" can be increased, but at great cost to performance and is not recommend (use the scroll api instead).
💪 Goal: always try to return less than 10,000 search results.
Simply put: "less is more" or rather "quality over quantity"

Solution: Use a minimum score
The easiest way to reduce the number of search results is to set a minimum score. This may seem obvious, but especially when using Kuromoji (morphilocial analysis) the results are often very noisy.
# Example using Searchkick library Company.search("リンカーズ会社", { body_options: { track_scores: true, min_score: 0.5 } })
Solution: Be specific of which fields to check against
Even if you've indexed all the attributes for a given model, it may be disadvantageous to search against all of them.
As an example, for a given model you've indexed: id, name, description, address, email, created_at, updated_at, ..
# The index looks like { id: .., name: .., description: .., address: .., email: .., created_at: .., updated_at: .., ... }
By default, searching will check all the index fields, but that may create negative results. Perhaps checking against email is not idea for privacy reasons, perhaps id or address are too generic, etc.. When searching, the best way to refine results is to be specific about which fields to check against.
So in this example, it may be advantageous to only search against name and description.
# Example using Searchkick library Company.search("リンカーズ会社", fields: [ "name", "description"], ...)
3. Be careful of using "order" (aka: sorting)
By default Elasticsearch sorts results based on a score, but if you're using the "order" property on a specific field (example: order by creation date) then score is ignored. The consequence of ignoring score is "👍 good-matches" and "👎 bad-matches" have equal opportunity to appear near the top of the list.
💡 "Order" is especially an issue when using an analyzer like Kuromoji where the match condition for a result is less obvious. As mentioned earlier, with the Kuromoji approach you are much more reliant on the score of the search results.
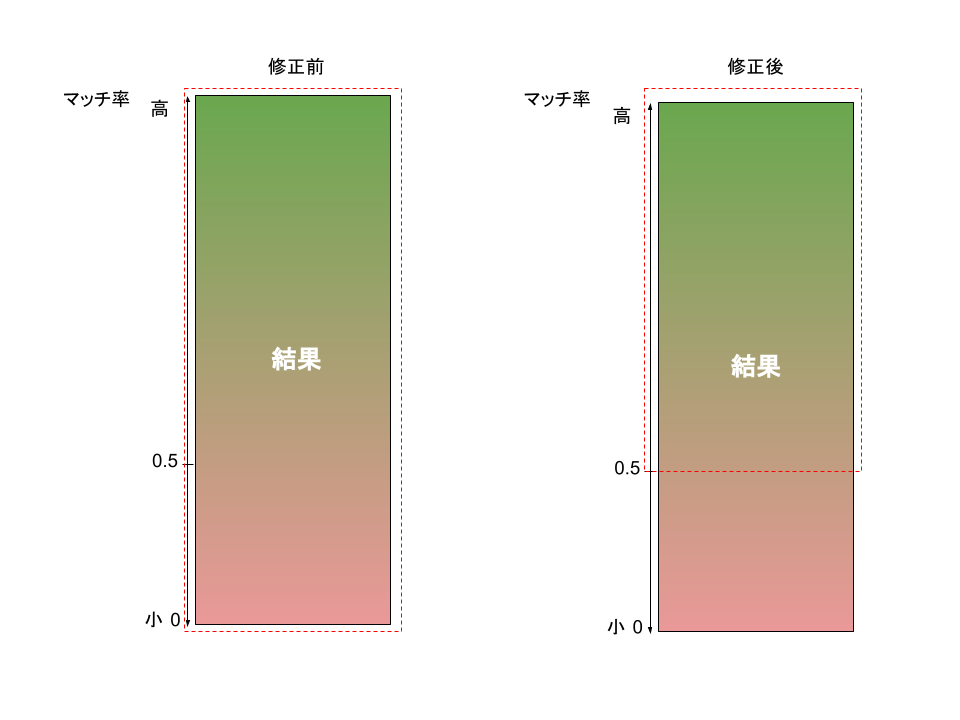
The easiest way to mitigate this issue is to track scores and use a minimum score when sorting. To do so, track_scores will need to be explicitly set to true.
# Example using Searchkick library Company.search("リンカーズ会社", { body_options: { track_scores: true, min_score: 0.5 } })
By enforcing a minimum score on sorted results, you're able to at least guarantee that the results have at least some level of relevance.
Recomendation
- Elasticsearch performs best when showing results based on match score, so avoid using a manual sort/order unless necessary
- If using a manual sort/order is necessary, use a minimum score to filter out noisy results
4. Choosing an Elasticsearch Gem (Ruby/Rails specific)
There are number of Ruby libraries that interface with Elasticsearch. Here are a few that we looked at:
1. Elasticsearch Ruby
This is the base Elasticsearch gem maintained by Elasticsearch (official). It contains the basic transport (client) and API layer to interact with Elasticsearch. All other Elasticsearch gems rely on this gem.
👍 Good:
- Maintained by Elasticsearch
- Does everything elastic search related
👎 Bad:
- Documentation is very poor
- Requires fairly extensive knowledge of Elasticsearch to use properly
- ❗ Elasticsearch Ruby >= v7.14 is no longer compatible with Amazon Elasticsearch (reference). A new forked version of the gem will be made available at some point. For now use v7.13 or ensure that you're using Elasticsearch hosted with Elastic.
2. Elasticsearch Rails
This is another gem maintained by the Elasticsearch team. It relies on ⬆️ Elasticsearch Ruby and adds a number of features that make it work nicely with Activerecord.
👍 Good:
- Maintained by Elasticsearch
👎 Bad:
- Documentation is very poor
- Not very well maintained
- Inherits some of the issues mentioned for Elasticsearch Ruby
3. Searchkick
A community written wrapper for Elasticsearch that's maintained by ankane. It relies on ⬆️ Elasticsearch Ruby and adds a number of features that make searching easy.
👍 Good:
- Easy to use
- Great documentation
- Advice on scaling
- Advice on indexing
- Ability to write SQL-like queries
- Actively updated
- Seems to be the perference of the Rails community
👎 Bad:
- There are gaps in the documentation for configuration.
- Here's an example of configuring a custom analyzer
- There is support for Japanese if you're using Kuromoji, but the library definitely performs the best with English.
- Not very useful unless you're using Rails.
❓ We use Amazon Elasticsearch. If Searchkick relies on Elasticsearch Ruby, will it break because of Elasticsearch 7.14?
No, Searchkick 4 is locked at Elasticsearch < 7.14.
The next version, Searchkick 5, will allow users to specify what distrubution they want to use (opensearch or elasticsearch).
So, what did we use?
We chose to use ✅ Searchkick. Overall the experience has been positive. For the basics and the happy-path it works great. The library does support extensive configuration, but the vast-majority of it is undocumented. You'll end up reading through the source code, referring to Elasticsearch Ruby's code (which is less documented), or Elasticsearch's general docs online.
Conclusion
Tuning Elasticsearch to fit your specific use-case is a continuous process. Don't expect to get it right the first time, but know that there are many ways to configure Elasticsearch the get the search results that match your customers needs. Especially when exposing Elasticsearch to the customer for the first time, it's worth strategizing ways to get feedback (logs, the customer directly, etc.) to know which things could be refined or adjusted to meet their specific needs.
Good luck!

Acknowledgements
Thank you to Samさん and Yokoyamaさん for the help. 🙏
References
Images provided by いらすとや