導入
情報システム部サービス開発チームのNathanです。この記事ではElasticsearchについて学んだことをご紹介します。横山さん、翻訳をしていただきありがとうこざいました。
The English version can be found here.
目的
Elasticsearchを設定して使用するためのガイドは数多くありますが、大部分は英語のデータを対象にしたものです。この記事は、そのほとんどが日本語で占められたデータをElasticsearchで扱う上で、もし最初にこれを知れていたら嬉しかったという知識を詰め込んでいます。

Elasticsearchのセットアップ手順は載っていますか?
載っていません。この記事は、日本語でElasticsearchを扱う時の手順を包括的に載せたものではありません。もしそういった内容を求める方は、以下のようなリンクを参考にしてください。
対象読者
- すでに日本語でElasticsearchを使用している、または今後使用する予定の開発者
- 今後RailsでElasticsearchを使用しようとしている開発者
プログラミング言語、ツールなど
この記事の多くの概念はコンピュータ言語を問わず普遍的なものですが、弊社ではRuby、特にRuby on Railsを利用しているため、例はRubyで書いています。
この記事の下の方にも、Ruby固有の内容をいくつか記載しています。
目次
- 導入
- 内容
- 結論
- 画像の出典
- 脚注
内容
1. 日本語インデックス戦略
Elasticsearchで何かを検索するには、最初にデータに対応したインデックスを作成する必要があります。インデックス作成の戦略は何通りもありますが、それぞれにメリット・デメリットがあります。デフォルトでは、Elasticsearchは日本語のインデックスを作成するように最適化されていませんが、簡単にするための方法やツールもあります。
何の問題や最適化について話しているのか
- 日本語の文法を理解する能力について
- 例: 単語の間にスペースがないため分析が困難
- 例: 動詞、形容詞などにはさまざまな活用形がある
- ひらがなで漢字を検索する機能、カタカナでひらがなを検索する機能などについて
- 日本語は全角・半角の両方で書かれることがあるため、どう扱うかについて
1A: 力技: N-gram解析
完全一致で検索する最も単純な方法をお探しの場合は、N-gram解析をお勧めします。
2 つの方法で単語をアナライズする 日本語は単語の切れ目がわかりにくいので、転置インデックスのキーは主に次の2つの手法で作成します。 (reference)
N-gramは戦略として、言語にとらわれない手法です。つまり、日本語、中国語、英語などあらゆる言語で機能します。
文字列長 n のチャンクに文字をグループ化し、それらのチャンクをインデックスするというのが基本的な概念です。Elasticsearchはこの解析を最初からサポートしており、外部のツールを使用する必要はありません。設定方法を記載したWebページは沢山あります。
👍 メリット
- 堅牢で予測可能
- 高速
👎 デメリット
- 検索時の入力は、結果と正確に一致する必要がある。1文字でも入力を間違えると、検索結果がすぐに台無しになる
- 単語を認識していないため、入力補完機能やひらがなで漢字を検索する機能などは上手くいかない
- ひらがなで漢字を検索したり、ひらがなでカタカナを検索したり、その逆をするための実装は難しくなる
1B: 形態素解析
KuromojiはAtilikia(アティリカ)社によってメンテナンスされているElasticsearchのアナライザ(analyzer)で、辞書を利用したインデックスを作成できます。

👍 メリット
- 漢字、ひらがな、カタカナを双方向に検索可能
- 動詞の活用など、さまざまな文法属性を認識可能
👎 デメリット
Kuromojiは、略語・新しい単語・俗語(スラング)などに弱いです。使用用途によっては、N-gramを使用した方が良い場合もあります。
形態素解析では、新語(未知語)に弱い。また、辞書ベースの場合、辞書にない単語は検出不能。(検索ノイズが少ないが、検索漏れが多い) (reference)
Kuromojiを利用すると、検索した時に得られるスコアにかなり依存することになります。また、N-gram解析ほど、検索文字列と検索結果が一致する理由は明白ではなくなります。これについては、記事の後半で詳しく説明します(大量の結果を扱う時の話)。
結局何を使ったの?
✅ 私達はKuromojiを選びました。私達の使用用途では、デメリットよりもメリットがはるかに上回りました。ただし、この手法を選択したことでいくつかのエッジケースをカバーする必要はありました。
2. 検索結果の数を減らす
Elasticsearchを最初に使い始めたとき、私達は顧客にできるだけ多くの検索結果を提供しようとしました。しかしすぐに、あまりにも多すぎる結果を返していることが明らかになり、戦略の修正を余儀なくされました。検索結果の数が1万を超えると、その必要性はさらに高まりました。
💡 Elasticsearchの「max_result_window」の大きさは1万です
"max_result_window"の値は、1万件の結果がメモリヒープに一度に置かれることを意味します。この閾値を超えた場合、検索一致の総数、検索順序、およびその他の多くの機能の値がたちどころに失われます。
"max_result_window"の値は増やせますが、パフォーマンスが大幅に低下するため、お勧めできません(代わりにScroll APIを使用してください)。
💪 目標: 常に1万件以内の値を返すよう心がけましょう。
シンプルに言うと、「少ない方が豊かである(※脚注1)」「量より質」ということですね。

解決策: 最小スコアを使う
検索結果の数を減らす最も簡単な方法は、最小スコアを設定することです。これは当たり前のように思えるかもしれませんが、特にKuromoji(形態学的分析)を使用すると、結果にノイズが入りがちです。
# Searchkickというライブラリ(gem)を使用した例 Company.search("リンカーズ株式会社", { body_options: { track_scores: true, min_score: 0.5 } })
解決策: 検索対象の項目を具体的に指定する
特定のモデルのすべての項目(attribute)にインデックスを付けたとしても、それらすべてに対して検索をかけるのは良くない場合があります。
例として、特定のモデルにインデックスを作成します。インデックスを作成する項目はid、name、description、address、email、created_at、updated_at...
## インデックスはこんな感じ
{
id: ..,
name: ..,
description: ..,
address: ..,
email: ..,
created_at: ..,
updated_at: ..,
...
}
デフォルトでは全てのインデックス項目が検索対象になりますが、それだとノイズが多くなります。「おそらくプライバシーの観点からEメールを検索対象にすることはないし、IDや住所も検索項目として向いていないし…」のように、検索結果を絞り込むための最良の方法は、チェックするフィールドを指定することです。
この例では、nameとdescriptionに対してのみ検索をかけるのが良いかもしれません。
# Searchkickというライブラリ(gem)を使用した例 Company.search("リンカーズ株式会社", fields: [ "name", "description"], ...)
3. "order"に気をつけろ (並べ替え)
デフォルトでは、Elasticsearchはスコアに基づいて結果を並べ替えますが、「order」プロパティを特定の項目で使用している場合(例:作成日をorderに指定して並べ替える)、スコアは無視されます。スコアが無視されると、検索時の入力に対して「👍 良く一致したもの」でも「👎 ほぼ一致していないもの」でも、同じように一覧のトップに表示されるようになってしまいます。
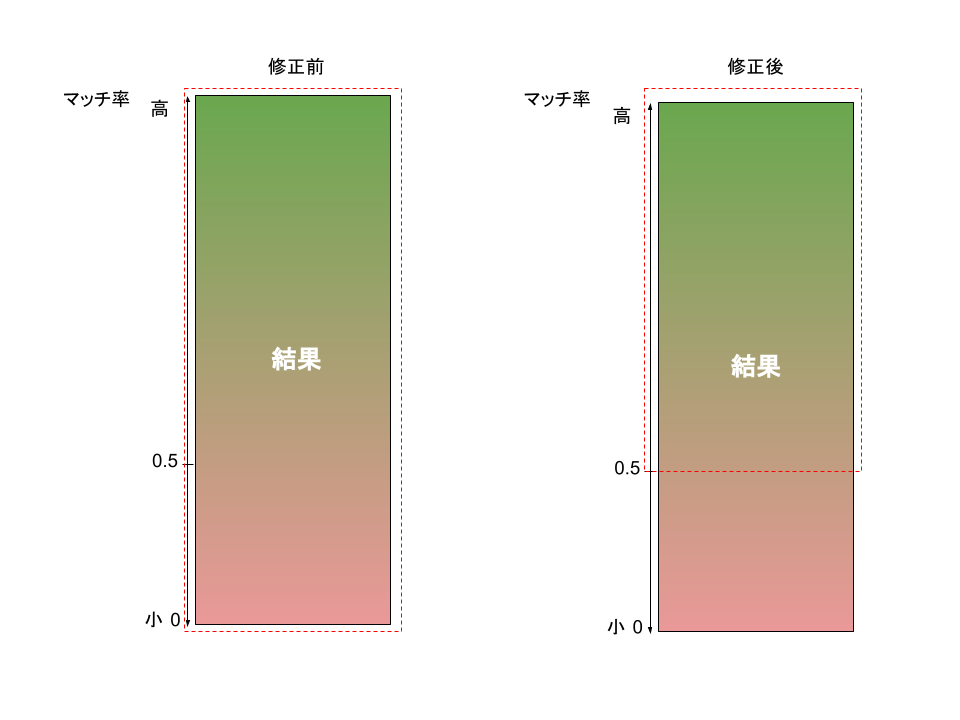
この問題を軽減するには、スコアを追跡し、並べ替え時に最小スコアを利用するのが手っ取り早いです。そのためには、track_scoresを明示的にtrueに設定する必要があります。
# Searchkickというライブラリ(gem)を使用した例 Company.search("リンカーズ会社", { body_options: { track_scores: true, min_score: 0.5 } })
ソートされた結果に最小スコアを適用することにより、結果に少なくともある程度の関連性があることを保証できます。
推奨
- Elasticsearchは、一致スコアに基づいて結果を表示するときに最高のパフォーマンスを発揮するため、必要な場合以外は、手動で並べ替えを行わないでください
- 手動の並べ替えを実装する必要がある場合は、最小スコアを使用してノイズの多い結果を除外してください
4. Elasticsearch Gemの選定 (Ruby/Rails)
Elasticsearchとの間でインターフェイスになってくれるRubyのライブラリは沢山あります。確認したうちのいくつかを紹介します。
1. Elasticsearch Ruby
Elasticsearch公式によってメンテナンスされている、基礎的なElasticsearchのgemです。このgemには、Elasticsearchと対話するための基となるクライアントやAPI層が含まれています。他のすべてのElasticsearch gemは、このgemに依存しています。
👍 メリット:
- Elasticsearchによってメンテされている
- Elasticsearch関連の全ての操作ができる
👎 デメリット:
- ドキュメントが貧弱
- 適切に使用するには、Elasticsearchに関するかなり広範な知識が必要 *❗ Elasticsearch Ruby は v7.14 以降、 Amazon Elasticsearch と互換性がなくなってしまった (参考) 。gemの新しいフォークがいつか利用できるようになりますが、今のところはv7.13を利用するか、Elastic社でホストされているElasticsearchを利用していることを確認してください。
2. Elasticsearch Rails
Elasticsearchチームによって維持されているもう1つのgemです。 Elasticsearch Rubyに依存しており、Activerecordと連携するための多くの機能が追加されています。
👍 メリット:
- Elasticsearch公式によってメンテされている
👎 デメリット:
- ドキュメントが貧弱
- あまりメンテされていない
- Elasticsearch Rubyで抱えている問題を継承している
3. Searchkick
ankane氏によって維持されているElasticsearch用のコミュニティで作成されたラッパーライブラリ。 Elasticsearch Rubyに依存しており、検索を容易にする多くの機能が追加されています。
👍 メリット:
- 簡単に使える
- ドキュメントが豊富
- スケール化の手引がある
- インデックス作成時の手引がある
- SQLのようなクエリで書くことができる
- 更新が活発
- Rubyコミュニティの好みに合いそう
👎 デメリット:
- 設定に関するドキュメントに穴がある
- カスタムアナライザを設定する例はこちら
- Kuromojiを使用している場合は日本語がサポートされるが、このgemは間違いなく英語で最高のパフォーマンスを発揮する
- Railsを使っていない場合はそんなに便利じゃない
❓ 質問: Amazon Elasticsearchを使用しています。SearchkickがElasticsearch Rubyに依存している場合、Elasticsearch 7.14が原因で壊れますか?)
いいえ、Searchkick 4 は Elasticsearch < 7.14 になるよう固定化されています。
次のバージョンであるSearchkick5では、ユーザーが使用するディストリビューション(opensearchまたはelasticsearch)を指定できます。
結局何を使ったか
✅ Searchkickを使用しました。全体的にはユーザー体験は良いものでした。基本的な使い方や正常系な使い方の場合は、とてもうまく動きました。ライブラリ自体は広範な設定をサポートしていますが、その大部分はドキュメント化されていません。最終的には、Elasticsearch Rubyのコード(あまりドキュメント化されていない)またはElasticsearchの一般的なドキュメントを参照して、ソースコードを読むことにはなります。
結論
特定のユースケースに合わせたElasticsearchの調整は、継続的に行っていく必要があります。最初から正しい結果になると思わない方が良いですが、Elasticsearchを構成して、顧客のニーズに合った検索結果を取得する方法はたくさんあるということは知っておいてください。特にElasticsearchを初めて顧客に公開する場合は、後から特定のニーズに合わせた改善や調整を行うために、フィードバック(ログ、顧客に直接など)の取得を戦略的に実施することは価値があります。
グッドラック!

画像の出典
脚注
- Less is More: 20世紀のドイツの建築家、ミース・ファン・デル・ローエが残した言葉